Co to jest Retrieval – Augmented Generation (RAG)?
RAG to skrót od Retrieval-Augmented Generation, techniki rozwoju sztucznej inteligencji, w której duży model językowy (LLM) jest połączony z zewnętrzną bazą wiedzy w celu poprawy dokładności i jakości jego odpowiedzi.
Typy źródeł, z którymi modele LLM mogą łączyć się za pomocą RAG, obejmują repozytoria dokumentów, pliki, interfejsy API i bazy danych.
Techopedia wyjaśnia znaczenie terminu RAG

Termin “Retrieval Augmented Generation” można przetłumaczyć na język polski jako “Generowanie wspomagane wyszukiwaniem”.
Ten termin odnosi się do procesu, w którym model generatywny, taki jak np.GPT, korzysta z dodatkowych informacji uzyskanych z zewnętrznych źródeł (retrieval) w celu poprawy dokładności i jakości generowanych treści.
Modele LLM wykorzystują funkcję Retrieval Augmented Generation, aby móc pobierać informacje z zewnętrznej bazy wiedzy. Zapewnia to modelowi dostęp do aktualnych, specyficznych dla domeny informacji, do których może się odwoływać, odpowiadając na monity użytkownika w czasie rzeczywistym.
Jedną z głównych zalet tego podejścia jest to, że wiedza modelu nie ogranicza się do danych szkoleniowych z określoną datą graniczną. Baza wiedzy może być również aktualizowana bez konieczności ponownego trenowania modelu.
Dostęp do zewnętrznego zasobu zmniejsza ryzyko wystąpienia halucynacji, w których LLM generuje weryfikowalnie fałszywe lub nieprawdziwe dane wyjściowe. Jednocześnie wyraźny link do bazy wiedzy ułatwia użytkownikom przeglądanie i sprawdzanie źródeł twierdzeń chatbota.
Teraz, gdy określiliśmy definicję generowanie wspomagane wyszukiwaniem, przyjrzyjmy się, jak to działa.
Jak działa Retrieval-Augmented Generation?
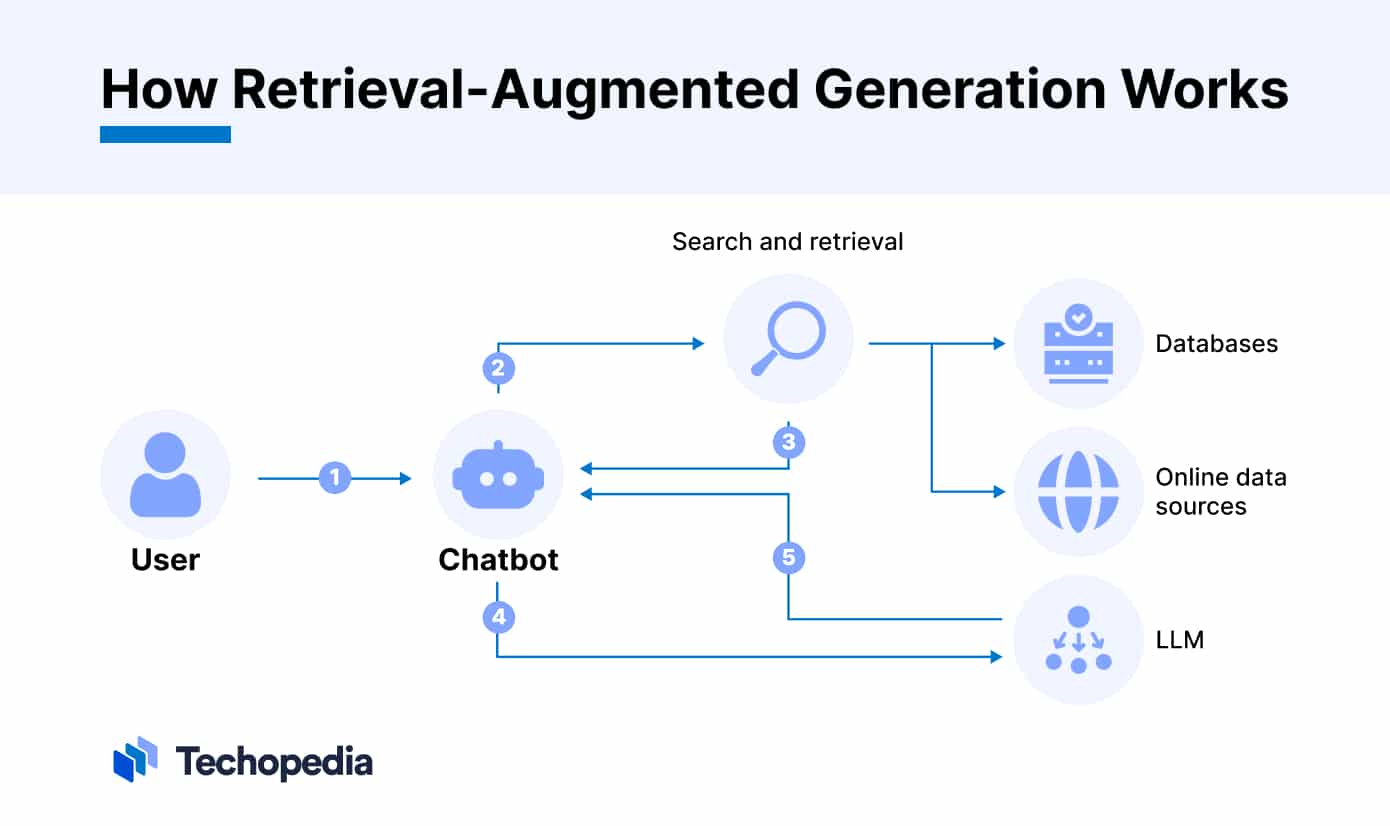
Na najwyższym poziomie RAG ma dwie główne fazy: fazę wyszukiwania i fazę generowania treści.
W fazie wyszukiwania algorytm uczenia maszynowego (ML) wykorzystuje przetwarzanie języka naturalnego (NLP) do identyfikacji istotnych informacji z bazy wiedzy.
Informacje te są następnie przekazywane do modelu generatora lub LLM, który wykorzystuje podpowiedź użytkownika i dane skompilowane w fazie wyszukiwania w celu wygenerowania odpowiedniej odpowiedzi, która jest zgodna z pierwotną intencją podpowiedzi. Proces ten opiera się na generowaniu języka naturalnego (NLG).
Historia RAG
Termin Retrieval Augmented Generation został pierwotnie stworzony w artykule badawczym zatytułowanym Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, opracowanym przez naukowców z Facebook AI Research, University College London i New York University.
W artykule tym wprowadzono koncepcję RAG i nakreślono, w jaki sposób można ją wykorzystać w zadaniach generowania języka w celu uzyskania bardziej szczegółowych i dokładnych wyników.
„Ta praca oferuje kilka pozytywnych korzyści społecznych w porównaniu z poprzednimi pracami: fakt, że jest silniej osadzona w rzeczywistej wiedzy faktograficznej (w tym przypadku Wikipedii), sprawia, że mniej »halucynuje« z generatorami, które są oparte na faktach i oferuje większą kontrolę i możliwość interpretacji” – czytamy w artykule.
Ponadto w badaniu zauważono, że „RAG może być wykorzystywany w wielu różnych scenariuszach z bezpośrednią korzyścią dla społeczeństwa, na przykład poprzez wyposażenie go w indeks medyczny i zadawanie mu otwartych pytań na ten temat lub pomagając ludziom być bardziej efektywnymi w ich pracy”.
Architectura RAG
Architektura RAG ma szereg podstawowych elementów, które umożliwiają jej funkcjonowanie. Składają się na nie następujące elementy:
Przypadki użycia RAG
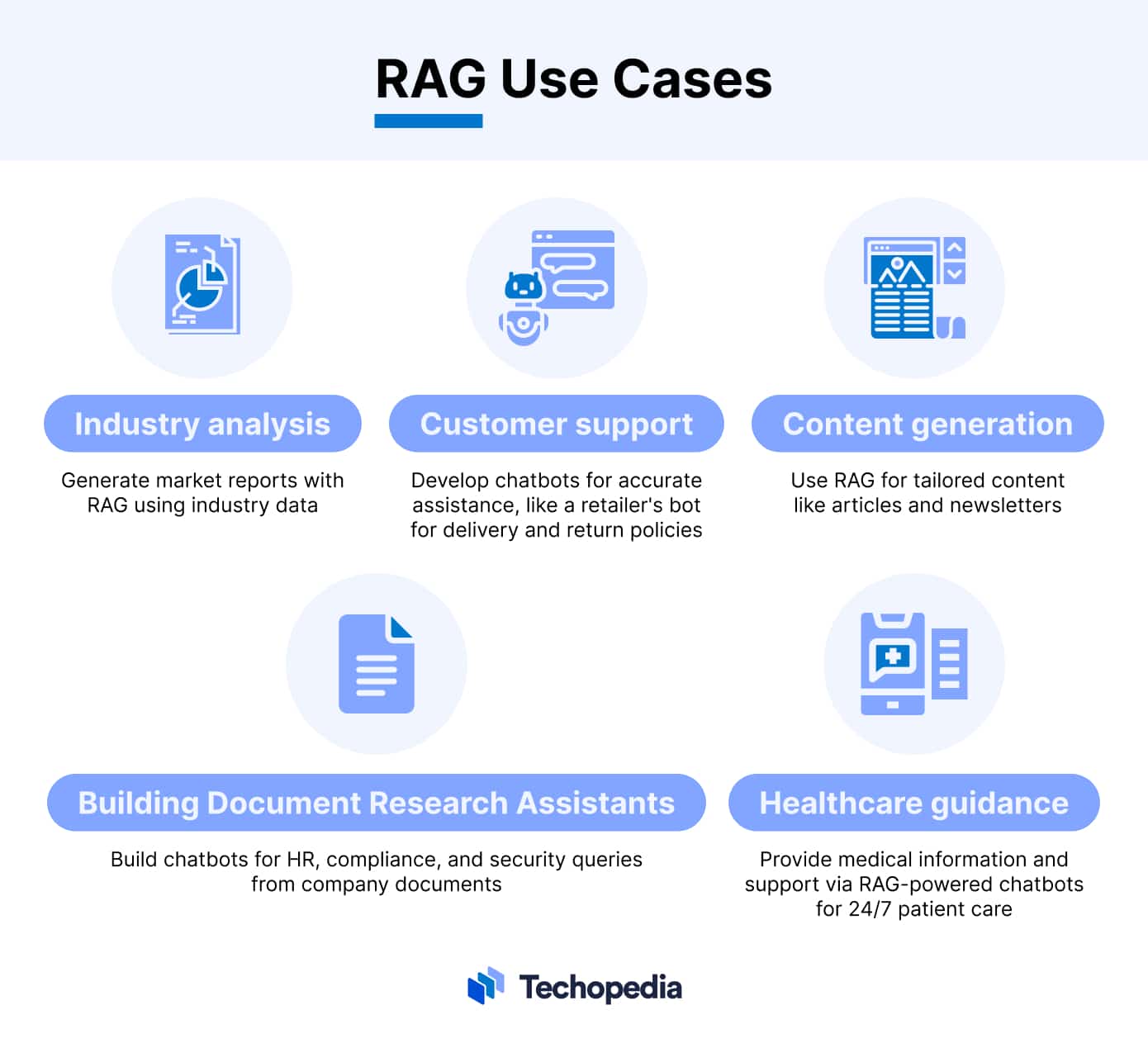
RAG oferuje wiele potencjalnych przypadków użycia dla przedsiębiorstw. Poniżej przyjrzymy się niektórym z najważniejszych z nich:
- Tworzenie asystentów wyszukujących dokumenty: Korzystanie z RAG umożliwia organizacjom tworzenie chatbotów, których pracownicy mogą używać do wyszukiwania danych przechowywanych w dokumentach firmy. Jest to przydatne do odpowiadania na pytania techniczne dotyczące tematów HR, zgodności i bezpieczeństwa.
- Obsługa klienta: Firmy mogą również wykorzystywać RAG do tworzenia chatbotów obsługi klienta, które zapewniają użytkownikom dostęp do dokładniejszych i bardziej wiarygodnych informacji. Na przykład, sprzedawca detaliczny może opracować chatbota, który jest przygotowany do odpowiadania na pytania użytkowników dotyczące zasad dostawy i zwrotów.
- Generowanie treści: Marketerzy mogą używać RAG do budowania specyficznych dla domeny LLM, które mogą tworzyć treści, takie jak artykuły, posty na blogach i biuletyny, które są dostosowane do potrzeb określonej grupy docelowej.
- Analiza branży: Podejmujący decyzje mogą również wykorzystywać modele językowe z RAG do tworzenia raportów z analiz rynkowych. Przykładowo, użytkownik może dodać dane rynkowe i raporty branżowe do bazy wiedzy, a następnie poprosić chatbota o podsumowanie kluczowych trendów.
- Opieka i doradztwo zdrowotne: Dostawcy usług medycznych mogą wykorzystywać RAG do tworzenia chatbotów, które mogą zapewnić pacjentom dostęp do informacji medycznych i wsparcia. Może to pomóc w zapewnieniu całodobowej opieki nad pacjentem, gdy lekarz nie jest dostępny.
Wyzwania RAG
Chociaż RAG jest niezwykle przydatnym sposobem tworzenia sztucznej inteligencji, nie jest idealny. Być może największym wyzwaniem związanym z korzystaniem z RAG jest to, że programista musi zbudować obszerną bazę wiedzy zawierającą wysokiej jakości treści referencyjne.
Jest to trudny proces, ponieważ dane muszą być starannie wyselekcjonowane. Jeśli jakość danych wejściowych jest niska, wpłynie to negatywnie na dokładność i wiarygodność wyników.
Podobnie, deweloperzy muszą również sprawdzić, czy baza wiedzy nie jest tendencyjna, stronnicza lub kultywuje jakieś uprzedzenia, którymi należy się zająć.
Wreszcie, chociaż RAG może pomóc zwiększyć niezawodność, nie może całkowicie wyeliminować ryzyka halucynacji, więc użytkownicy końcowi nadal muszą zachować ostrożność, ufając wynikom.
Plusy i minusy RAG
Jako technika, RAG ma zarówno zalety, jak i wady. Poniżej przyjrzymy się niektórym z jej najważniejszych korzyści i słabości.
Zalety
- Połączenie z bazą wiedzy specyficzną dla danej domeny zapewnia bardziej precyzyjne wyszukiwanie informacji i zmniejsza liczbę błędnych informacji.
- Aktualizacja bazy wiedzy zamiast ponownego szkolenia modelu oszczędza czas i pieniądze programistów.
- Użytkownicy uzyskują dostęp do cytatów i odniesień, co ułatwia sprawdzanie faktów.
- Wyniki specyficzne dla danej domeny skuteczniej zaspokajają wyspecjalizowane potrzeby użytkowników
Wady
- Bez wysokiej jakości danych, jakość wyników może być niska.
- Budowanie dużej bazy wiedzy wymaga znacznego czasu i organizacji.
- Błędy w danych szkoleniowych mogą wpływać na wyniki.
- Nawet przy zwiększonej dokładności istnieje ryzyko halucynacji
Podsumowanie
RAG jest cenną technologią zwiększającą podstawowe możliwości LLM. Dzięki odpowiedniej bazie wiedzy deweloper może zapewnić użytkownikom dostęp do ogromnej ilości wiedzy specyficznej dla danej domeny.
Biorąc to pod uwagę, użytkownicy nadal muszą być proaktywni w zakresie sprawdzania faktów pod kątem halucynacji i innych błędów, aby uniknąć dezinformacji.
FAQs
Czym w uproszczeniu jest generowanie wspomagane wyszukiwaniem?
Jakiego rodzaju informacje są wykorzystywane w RAG?
Czy RAG jest tym samym co generatywna sztuczna inteligencja?
Co oznacza RAG w programach LLM?
References
- Co to jest duży model językowy LLM? (OVHcloud)
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Arxiv)
- Facebook robi zamieszanie w świecie AI (Wyborcza.biz)
- Czym jest Retrieval-Augmented Generation? (Born Digital)









